
Marketing & IA frugale : comment concilier performance, maîtrise budgétaire et transition écologique ?
à propos du marketing et de l'IA frugale
Pour les CMO, l’enjeu est double : maîtriser les coûts (des factures d’inférence explosives aux shadow AI incontrôlées) et réconcilier innovation et responsabilité. Entre routage intelligent des modèles, optimisation des prompts, et gouvernance stricte, une nouvelle discipline émerge : l’IA frugale. Non pas une contrainte, mais un levier de différenciation pour ceux qui sauront concilier agilité, ROI, et sobriété.
Comment y parvenir ? Cet article décrypte les réflexes stratégiques, les pièges à éviter, et les outils concrets pour faire de l’IA un allié durable en réduisant les risques de gaspillage.
L'IA frugale by design #UnMUST
En 2025, l’empreinte carbone globale des systèmes d’IA est estimée à près de 80 millions de tonnes de CO2. Cela représente un niveau d’émissions équivalent à celui d’une ville majeure comme New York.
(*) The Guardian
L’Agence Internationale de l’Énergie anticipe qu’avec le développement massif de l’IA générative, la consommation électrique des centres de données dans le monde va doubler d’ici fin 2026 pour atteindre le seuil critique des 1 000 TWh.
(*) L’Agence Internationale de l’Energie
À l’échelle mondiale, les experts estiment que la consommation d’eau liée aux systèmes d’IA pourrait atteindre le chiffre faramineux de 765 milliards de litres en 2025.
(*) The Guardian
Cartographie des coûts liés à l'utilisation des IA (financiers et énergétiques) : quand l'innovation rencontre ses limites financières et environnementales
L’intelligence artificielle est souvent présentée comme un levier de croissance inépuisable, mais son déploiement massif révèle une réalité moins reluisante : derrière chaque requête, chaque modèle entraîné ou chaque agent autonome se cachent des coûts colossaux financiers, énergétiques et environnementaux. Entre dizaines de millions de dollars pour l’entraînement d’un LLM, factures d’inférence explosives (70% des coûts totaux), et empreintes carbone comparables à celles de métropoles entières, l’IA pèse lourd dans les bilans des entreprises et de la planète.
Pire, ces coûts ne se limitent pas aux dépenses directes : consommation d’eau équivalente à celle de pays, dépendance technologique risquée, et maintenance invisible (jusqu’à 20% du coût initial par an) transforment l’IA en un défi systémique. Dans ce chapitre, je parcours l’intégralité de ces coûts cachés ou méconnus, pour mieux comprendre pourquoi la sobriété n’est plus une option, mais une nécessité stratégique.
1. Les différents types de coûts financiers
- Les coûts d’entraînement : développer un grand modèle de langage (LLM) nécessite des investissements initiaux faramineux, s’élevant à des dizaines, voire des centaines de millions de dollars pour un seul cycle d’apprentissage.
- L’inférence par API : il s’agit du coût d’utilisation au quotidien, qui représentera au moins 70% des coûts totaux sur la durée de vie d’un modèle, éclipsant de loin les coûts d’entraînement. Les requêtes sont facturées à l’utilisation selon le volume de « tokens » (par exemple, 30 à 60 dollars par million de tokens pour GPT-4), et ces dépenses peuvent s’envoler avec la longueur des requêtes et le choix du modèle.
- Les coûts d’intégration et de licences : l’intégration de l’IA dans les systèmes existants de l’entreprise coûte entre 50 000 et 500 000 dollars. Il faut y ajouter les licences logicielles (jusqu’à plus de 100 000 dollars par an) et la formation des équipes (25 000 à 100 000 dollars).
- Les coûts cachés et de maintenance : la maintenance et la surveillance des modèles représentent 15 à 20% du coût de construction chaque année. L’utilisation d’agents autonomes génère également un « choc de facturation » : en cas de boucles de raisonnement, un agent peut lancer des milliers d’appels API onéreux de manière autonome avant qu’un humain ne s’en aperçoive. Enfin, la dépendance technologique (Vendor Lock-in) expose les entreprises à des augmentations soudaines de tarifs de la part des fournisseurs.
2. Les différents types de coûts énergétiques
- La consommation de l’entraînement : phase extrêmement intensive, l’entraînement de Llama 3.1 8B par Meta a consommé 21 GWh d’électricité, tandis que GPT-3 a nécessité 1,3 GWh.
- La consommation de l’inférence : l’usage de l’IA au quotidien est très énergivore, une requête textuelle simple pour GPT-3 consommant environ 4 Wh. À grande échelle et sur la durée, la phase d’inférence dépasse l’entraînement, pouvant représenter jusqu’à 65% de l’impact environnemental total d’un modèle massivement utilisé. De plus, générer une image consomme en moyenne 60 fois plus d’énergie que de générer du texte.
- L’énergie de fabrication (matérialité) : la construction des puces, des serveurs et des centres de données nécessite une extraction massive de métaux critiques et énormément d’énergie. En France, la fabrication des équipements représente environ 60% de l’empreinte carbone totale du secteur numérique.
- La consommation latente (coûts cachés d’infrastructures) : maintenir les serveurs de stockage, les réseaux et le refroidissement allumés consomme énormément d’énergie même lorsqu’aucune requête n’est traitée (Idle power). Pour le modèle BLOOM, cette consommation passive a représenté près de 29% des émissions totales générées pendant son entraînement.
3. L'empreinte carbone des intelligences artificielles
- À l’échelle globale : en 2025, l’empreinte carbone mondiale des systèmes d’IA est estimée à près de 80 millions de tonnes de CO2, ce qui est comparable aux émissions d’une grande ville comme New York.
- Lors de l’entraînement : entraîner GPT-3 a généré 552 tonnes de CO2 (soit environ 200 vols aller-retour Paris-New York). L’entraînement de Llama 3.1 8B a émis près de 9 000 tonnes de CO2. En revanche, le modèle BLOOM, entraîné en France, n’a émis que 25 à 50 tonnes de CO2 grâce à un mix énergétique dominé par le nucléaire.
- Lors de l’inférence : Seulement sur le mois de janvier 2023, l’utilisation de ChatGPT aurait généré 10 113 tonnes de CO2, soit l’équivalent des émissions annuelles de 1 264 foyers français. Avec l’arrivée de modèles plus puissants comme o3 d’OpenAI, une seule résolution de problème mathématique complexe peut générer jusqu’à 684 kg de CO2, ce qui équivaut à cinq pleins d’essence.
- L’impact sur les géants de la Tech : l’explosion des besoins en IA met en péril les objectifs de neutralité carbone des GAFAM : les émissions de CO2 de Microsoft ont bondi de 30% et celles de Google de 48% en cinq ans (2019-2024) en raison de la construction de nouveaux centres de données.
4. La consommation d'eau associée à l'IA
- À l’échelle globale : la consommation d’eau des systèmes d’IA pourrait atteindre 765 milliards de litres en 2025, soit l’équivalent de la moitié de la consommation annuelle d’un pays comme le Royaume-Uni.
- À l’échelle d’une requête : Une conversation typique avec une IA générative (entre 10 et 50 requêtes) entraîne la consommation d’environ 500 ml d’eau fraîche, soit l’équivalent d’une petite bouteille d’eau.
- Consommation globale des entreprises : l’eau est vitale pour refroidir les serveurs et rincer les composants lors de la fabrication des semi-conducteurs. La consommation d’eau combinée de Microsoft et Google a augmenté de 99% entre 2020 et 2024, atteignant 36,6 millions de mètres cubes.
- Conflits d’usage et stress hydrique : cette surconsommation se fait souvent au détriment des besoins agricoles ou citoyens locaux. Google rapporte par exemple qu’environ 14% de l’eau que l’entreprise consomme provient de zones exposées à un risque élevé de pénurie ou de stress hydrique.
L’IA à l’ère de la sobriété : quand l’explosion des budgets révèle l’urgence d’une révolution stratégique
Cette croissance que j’évoque en introduction cache des risques majeurs : dérives financières (coûts de production sous-estimés jusqu’à 1 000 %, boucles récursives d’agents autonomes), dépendance technologique (vendor lock-in aux géants comme OpenAI ou Microsoft), et aberration économique (un million de requêtes coûtent 45 000 $ avec GPT-4 contre 250 $ avec un SLM comme Mistral 7B).
Pire, le paradoxe de Jevons se profile : les gains d’efficacité des SLM et de l’optimisation stimulent une demande industrielle, faisant exploser l’empreinte carbone (ex. : +48% d’émissions CO₂ pour Google en 5 ans). Face à ce constat, quelle est la solution ? Le FinOps IA : guardrails budgétaires, routage intelligent vers des SLM, et une frugalité systématique pour réserver la puissance des LLM aux seuls cas critiques. Une transition indispensable pour éviter l’effondrement financier et écologique.
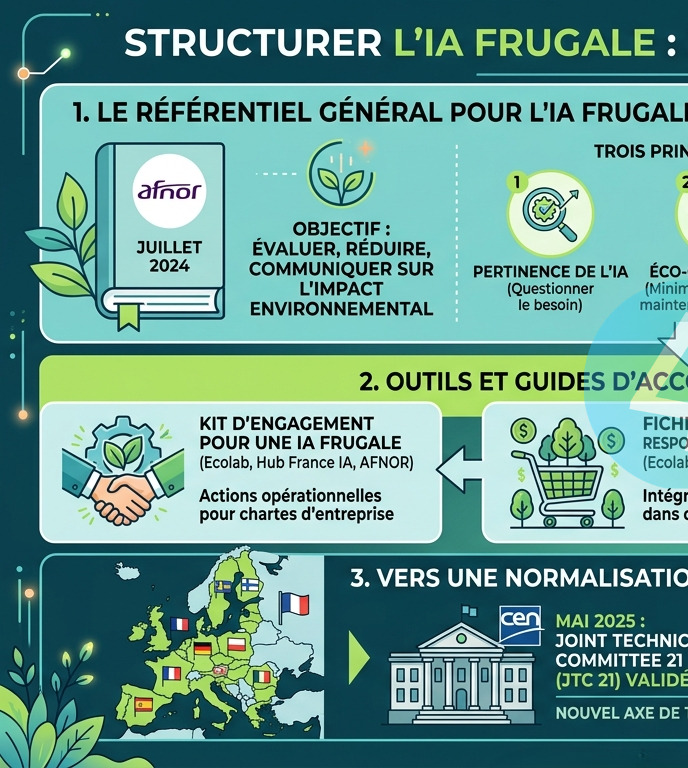
De plus, les entreprises ne peuvent plus se contenter de bonnes pratiques isolées. C’est là qu’intervient le Référentiel Général pour l’IA Frugale (AFNOR Spec 2314), première norme française dédiée à une IA sobre, responsable et maîtrisée.
| Comparatif | Small Language Models (SLM) | Large Language Models (LLM) |
|---|---|---|
| 💸 Coût d’inférence | Très bas : ~0,25 $ par million de tokens (ex : Mistral 7B). Économie de 180x vs. GPT-4. | Élevé : 30 à 60 $ par million de tokens (ex : GPT-4). Peut exploser avec des requêtes longues ou complexes. |
| 📊 Intégration | Simple : Compatible avec des infrastructures légères. Idéal pour les PME/startups. | Complexe : Nécessite des intégrations lourdes (API, cloud), des compétences techniques avancées. |
| ⚙️ Performance | Rapide et efficace pour des tâches ciblées. Précision élevée si le modèle est finement entraîné sur des données first-party. | Polyvalent et puissant : Meilleure compréhension du contexte, capacité à gérer des requêtes ambiguës ou ouvertes. Meilleure créativité pour des contenus originaux. |
| 🌍 Impact environnemental | Limité : Idéal pour une IA sobre. Peut fonctionner sur des data centers verts (ex : mix nucléaire en France). | Majeur : Contribue à l’augmentation des émissions des GAFAM (+30 à +48 % en 5 ans pour Microsoft/Google). Risque de paradoxe de Jevons (plus d’usage = plus d’impact). |
| 💰 Coût d’entraînement | Faible : Quelques milliers à dizaines de milliers d’€ (ex : Mistral 7B, Llama 3.1 8B). Peut être entraîné en on-premise ou sur des infrastructures légères. | Élevé : Dizaines à centaines de millions de $ (ex : GPT-4, Claude Opus). Réservé aux géants du cloud (OpenAI, Google, Meta). |
| ⚡ Consommation énergétique | Faible : ~0,1 Wh par requête (ex : Llama 3.1 8B). Empreinte carbone réduite (ex : 25-50 tonnes CO₂ pour BLOOM). | Élevée : ~4 Wh par requête (GPT-3). Entraînement = 1,3 à 21 GWh (ex : GPT-3, Llama 3.1 8B). Empreinte carbone massive (ex : 552 tonnes CO₂ pour GPT-3). |
| 🔧 Flexibilité | Élevée : Peut être déployé en on-premise (souveraineté des données), personnalisé pour des besoins spécifiques. | Faible : Dépend des API des fournisseurs (OpenAI, Google, etc.). Peu de contrôle sur les mises à jour ou les tarifs. |
| 🎯 Recommandation pour les CMO | À privilégier pour 90 % des tâches marketing : – Routage intelligent (model cascading) : Utiliser les SLM pour les requêtes simples, réserver les LLM aux 10 % de cas complexes. – Économie immédiate : Réduction de 60 à 87 % des coûts d’inférence. – Sobriété garantie : Aligné avec les objectifs RSE et le référentiel AFNOR Spec 2314. | À réserver aux cas critiques : – Justification obligatoire : Vérifier que la valeur ajoutée (ex : gain de conversion, insight stratégique) justifie le coût. – Guardrails stricts : Limiter le nombre de tokens, imposer des hard caps pour les agents autonomes. – Hybridation : Combiner LLM (pour la créativité) et SLM (pour l’exécution) pour optimiser coûts et performance. |
| 🎯 Cas d’usage marketing | ✅ Optimaux pour : – Classification de données (ex : segmentation clients). – Génération de contenus simples (ex : posts réseaux sociaux, emails standardisés). – Chatbots basiques (FAQ, SAV niveau 1). – Extraction d’informations (ex : analyse de sentiments sur des avis clients). – Tâches répétitives (ex : tagging automatique de produits). | ✅ Indispensables pour : – Raisonnement complexe (ex : stratégie de predictive lead scoring). – Génération de contenus créatifs (ex : scripts vidéo, storytelling avancé). – Compréhension contextuelle fine (ex : analyse de tendances marché, synthèses stratégiques). – Chatbots avancés (ex : assistance client avec nuance émotionnelle). – Traitement multilingue à grande échelle. |
| ⚠️ Limites | – Manque de nuance : Difficile pour les tâches nécessitant un raisonnement profond ou une créativité élevée. – Moins polyvalent : Doit être spécialisé pour chaque cas d’usage. – Données d’entraînement : Nécessite des jeux de données propres et structurés pour éviter les biais. | – Coût prohibitif pour un usage massif. – Risque de surconsommation : Boucles de raisonnement (reasoning loops), prompt bloat. – Dépendance technologique (Vendor Lock-in) : Difficile à remplacer ou migrer. – Opacité : Moins contrôlable, risque d’hallucinations ou de biais cachés. |
Le Référentiel Général pour l'IA Frugale (AFNOR Spec 2314)
Publié en juillet 2024 par l’AFNOR et le ministère de la Transition écologique (via l’Ecolab), ce référentiel est le texte fondateur en France pour structurer et normaliser la démarche d’IA frugale. Il a été élaboré avec la contribution de plus d’une centaine d’experts.
Objectif : fournir des méthodologies précises pour évaluer, réduire et communiquer sur l’impact environnemental des projets d’IA, et ce, de leur conception jusqu’à leur mise hors service.
Trois principes cardinaux :
- Démontrer la pertinence et la nécessité absolue de recourir à l’IA plutôt qu’à une solution technologique moins gourmande.
- Adopter de bonnes pratiques d’éco-conception pour minimiser les besoins en ressources matérielles et énergétiques sans sacrifier la performance.
- Questionner les finalités et les usages pour s’assurer qu’ils s’inscrivent dans le respect des limites planétaires.
Structure opérationnelle : Le document se compose de 31 fiches de bonnes pratiques classées selon 7 thématiques clés : la gouvernance, la qualification du besoin, l’optimisation des performances des modèles, la gestion optimisée des données, l’analyse de l’impact des équipements matériels, la mesure de l’impact environnemental, et enfin la gestion des compétences et l’acculturation des équipes.
Les outils et guides d’accompagnement nationaux
Afin de faciliter la mise en œuvre de cette frugalité au quotidien, plusieurs initiatives et déclinaisons ont vu le jour :
- Le Kit d’engagement pour une IA frugale : conçu par l’Ecolab, le Hub France IA et l’AFNOR, il propose une liste d’actions opérationnelles et atteignables que les organisations privées comme publiques peuvent intégrer directement dans leurs chartes d’entreprise ou chartes éthiques.
- La Fiche pratique « Achat Responsable de solutions d’IA » : publiée en décembre 2025 par l’Ecolab, la DINUM et la Direction des achats de l’État (DAE), ce guide opérationnel aide les organisations à décrypter les impacts environnementaux d’une solution et à intégrer des exigences de sobriété lors de la commande publique ou du sourcing de prestataires.
- Le RGESN (Référentiel général d’écoconception des services numériques) : issu de la loi REEN de 2021 et co-piloté par l’Arcep, l’Arcom et l’ADEME, ce cadre plus large fournit des recommandations pour réduire l’empreinte environnementale dès la conception de n’importe quel service numérique, ce qui inclut naturellement les outils basés sur l’intelligence artificielle.
Vers une normalisation à l’échelle européenne
La démarche française de normalisation de l’IA frugale s’exporte désormais à l’échelle européenne. Le Comité Européen de Normalisation (CEN), à travers son « Joint Technical Committee 21 » (JTC 21), a validé en mai 2025 un nouvel axe de travail portant sur les lignes directrices et les métriques de l’impact environnemental de l’IA. L’objectif est de combler le manque de littérature normative internationale en définissant des méthodes de calcul partagées et de promouvoir des outils de mesure accessibles aux entreprises, afin que celles-ci puissent concevoir des modèles d’IA frugaux et se différencier sur le marché.

Marketing et IA frugale : les réflexes stratégiques pour les CMO
Ne tombez pas dans le piège du « toujours plus grand ». Réservez les modèles de pointe (LLM type GPT-4) aux 10% de requêtes nécessitant un raisonnement complexe. Pour les 90% restants (classement, SAV, requêtes simples), orientez-vous vers des Small Language Models (SLM) beaucoup moins coûteux et moins énergivores.
Abandonnez l’analyse de la facture globale en fin de mois pour exiger de vos équipes une télémétrie unitaire. Il s’agit de calculer exactement le « coût par résultat » (combien coûte la génération d’un lead précis ou d’un article par l’IA) pour garantir que le coût technologique ne détruit pas la valeur commerciale générée.
Conditionnez le lancement de tout nouveau workflow marketing ou agent IA à une estimation rigoureuse de son coût à grande échelle cible avant son déploiement en production. Cette anticipation évite de découvrir l’explosion des factures d’inférence une fois la campagne lancée.
La vitesse de l’IA ne doit pas primer sur la pertinence et la sécurité de la marque. Les données montrent qu’un contenu hybride (par exemple 60% généré par IA et 40% édité par un humain avec des données propriétaires) obtient de bien meilleures performances d’attention qu’un texte 100% automatisé, tout en évitant les hallucinations.
Traitez la conception des requêtes comme une discipline financière. Réduisez agressivement la longueur des « system prompts », forcez l’IA à répondre dans des formats structurés (comme JSON, plus économique), et utilisez la mise en cache (prompt caching) pour que l’IA ne recalcule pas les mêmes consignes de base à chaque interaction.
Faites l’inventaire de vos 10 cas d’usage qui consomment le plus de tokens. Pour chacun, vérifiez s’il est possible de l’optimiser. Ensuite, désignez un responsable précis (ownership) de ces coûts : sans propriétaire clairement identifié entre le marketing et la technique, l’optimisation ne sera jamais durable.
Ne payez pas le prix fort du « temps réel » quand ce n’est pas nécessaire. Pour la classification en masse, la génération de rapports ou l’analyse de gros volumes de documents en arrière-plan, utilisez les API asynchrones (par lots), qui permettent généralement d’économiser jusqu’à 50% sur les tarifs d’inférence.
Les agents IA peuvent entrer dans des boucles de réflexion infinies s’ils rencontrent un obstacle. Pour éviter les chocs de facturation majeurs, imposez toujours des limites dures (hard caps) quant au nombre d’itérations et d’appels API qu’un agent autonome est autorisé à faire pour accomplir une tâche marketing.
Plutôt que d’accumuler des lacs de données immenses, affinez vos modèles sur des jeux de données restreints mais très qualitatifs (« small data ») issus de vos bases propriétaires. Appliquée au ciblage contextuel, cette approche maintient des taux de conversion très élevés, tout en respectant le RGPD et l’abandon des cookies tiers.
Ne lancez pas une transformation totale et simultanée de tous vos canaux. Commencez par sélectionner très peu de cas d’usage (ex: support client de premier niveau ou qualification de leads) en vous assurant d’abord que les données qui alimentent l’IA sont parfaitement structurées, propres et unifiées.
Exemples de succès : Optimisation du ROI grâce à une IA plus sobre
- Innovaccer et Aviva : ces deux entreprises ont mis en place des passerelles d’IA (AI Gateways) comme TrueFoundry pour centraliser et contrôler leurs flux. En imposant des limites strictes de tokens par équipe et en appliquant un routage intelligent, elles ont réussi à réduire leur facture d’IA de 40 à 60%, éliminant les requêtes inutiles vers des modèles surdimensionnés.
- Microsoft avec DynamoLLM : pour optimiser les performances de ses propres systèmes d’inférence, l’entreprise a développé un cadre de gestion dynamique de l’énergie. Ce système a permis de réduire la consommation énergétique de 53%, les émissions de carbone de 38% et les coûts opérationnels de 61%, prouvant qu’une infrastructure sobre génère un ROI direct.
- Klarna : en utilisant des frameworks open-source comme LangGraph pour créer des workflows flexibles et ciblés, l’entreprise a déployé un bot de support client capable de servir 85 millions d’utilisateurs. Cette automatisation efficace a permis une réduction de 80% des temps de résolution.
- Dove (La frugalité par le refus) : dans sa campagne « The Code » en 2025, Dove a pris le parti de ne pas utiliser d’images générées par l’IA pour représenter des femmes. Ce choix éthique et radical s’est transformé en avantage concurrentiel majeur, renforçant la confiance de sa clientèle face aux concurrents inondant le marché de visuels IA peu coûteux mais artificiels.
Erreurs classiques et écueils budgétaires de l'IA
- Utiliser un modèle surpuissant pour des tâches simples : c’est l’erreur la plus commune. Par facilité, de nombreuses entreprises configurent toutes leurs requêtes par défaut sur les modèles les plus avancés (et les plus chers) du marché. Pourtant, pour des tâches de classification, d’extraction de données ou de questions-réponses courtes, les grands modèles n’apportent aucune valeur ajoutée par rapport aux petits modèles (SLM) qui pourraient accomplir la même tâche pour une fraction du coût.
- Les boucles infinies d’agents autonomes (« reasoning loops ») : déployer un agent IA sans imposer de limite (hard caps) à son raisonnement. Face à un obstacle, un agent mal configuré peut entrer dans une boucle récursive et générer de manière autonome des milliers d’appels API onéreux en quelques heures, provoquant un véritable choc de facturation.
- La saturation des systèmes RAG (Retrieval-Augmented Generation) : de nombreuses implémentations RAG injectent d’énormes quantités de documents non pertinents dans la fenêtre de contexte de l’IA. Résultat : 70 à 80% des tokens envoyés et facturés sont inutiles, et l’entreprise paie pour un contexte que le modèle finit par ignorer.
- Le « shadow AI » et l’absence de gouvernance : laisser différentes équipes utiliser des clés API sans taguer l’utilisation, ni imposer de budgets par département. Les dépenses deviennent invisibles au quotidien, et les anomalies de coûts ne sont découvertes que plusieurs semaines plus tard, à la réception de la facture cloud.
- Le « prompt bloat » (l’inflation silencieuse des requêtes) : utiliser des instructions système (system prompts) inutilement longues ou demander des réponses en texte libre plutôt que dans des formats structurés (comme JSON). Un format JSON permet généralement d’économiser 40% des tokens de sortie. Répéter du contexte statique sans utiliser la « mise en cache des prompts » (prompt caching) oblige également à payer pour le même traitement à chaque nouvelle requête.
- Négliger le traitement asynchrone : exiger un traitement en temps réel (qui est très cher) pour des processus en arrière-plan comme la classification en masse ou la génération de rapports différés. L’utilisation d’API asynchrones permet pourtant d’obtenir jusqu’à 50% de réduction tarifaire.
La boite à outils avec des solutions clés
- Mistral 7B : un modèle open-source extrêmement économique (facturé environ 0,25 à 0,30 dollar par million de tokens). Il permet de réaliser jusqu’à 180x d’économies par rapport à un modèle massif pour des tâches routinières (SAV, classification).
- Phi-3-mini (Microsoft) : avec ses 3,8 milliards de paramètres, il est conçu pour l’efficacité pure et peut fonctionner localement sur un seul GPU, des CPU, ou directement sur des appareils « Edge » comme des téléphones, garantissant la souveraineté des données.
- Claude Haiku (Anthropic) : un modèle très rapide et ultra-économique (0,80 $ en entrée et 4 $ en sortie par million de tokens), idéal pour prendre en charge 90% des requêtes simples dans une stratégie de routage intelligent (Model Cascading).
- TrueFoundry : une passerelle d’IA (AI Gateway) incontournable pour imposer des limites strictes (hard caps) de budget par équipe. Elle applique un routage intelligent des requêtes et intègre des « coupe-circuits » automatiques pour stopper les agents IA bloqués dans des boucles infinies. Elle permet de réduire les coûts d’inférence de 40 à 60%.
- Neutrino AI Router : un outil d’orchestration qui analyse la complexité de chaque requête avant traitement pour l’envoyer instantanément au modèle le plus adapté (SLM ou LLM), éliminant ainsi le gaspillage lié à l’utilisation systématique de modèles onéreux.
- Cloudchipr : une plateforme FinOps offrant une télémétrie unitaire : elle centralise la visibilité des coûts cloud/IA, détecte les anomalies de facturation en temps réel et automatise les recommandations pour réduire les dépenses inutiles.
- Airia : une autre passerelle d’IA de référence permettant de centraliser l’accès aux modèles, d’appliquer des limites de requêtes (rate limiting) et d’assurer une gouvernance financière stricte des déploiements agentiques.
- DynamoLLM (Microsoft) : un framework d’ingénierie de pointe dédié à la gestion dynamique de l’énergie. Appliqué aux clusters d’inférence, il est capable de réduire la consommation d’énergie de 53%, les émissions de carbone de 38% et les coûts opérationnels de 61%.
- Green Algorithms : un outil open source simple, développé à l’Université de Cambridge, permettant d’estimer très tôt la consommation énergétique et l’impact carbone d’un système d’IA.
- CodeCarbon : un package Python qui s’intègre au code des développeurs pour mesurer en temps réel la consommation électrique et l’empreinte carbone générées par l’exécution d’une IA sur un serveur.
- EcoLogits & compar:IA : EcoLogits est une bibliothèque (utilisée notamment par le Groupe Orange) qui surveille l’impact environnemental des API d’IA. Le service compar:IA (développé par le gouvernement français) permet de tester à l’aveugle deux modèles pour comparer leurs performances et l’empreinte carbone spécifique à chaque requête.
- LangGraph & LangChain : les frameworks open-source de référence pour créer des workflows d’agents flexibles. Ils ont par exemple été utilisés par Klarna pour déployer un bot de support client très optimisé, servant 85 millions d’utilisateurs.
- Microsoft AutoGen & CrewAI : des frameworks d’orchestration multi-agents. AutoGen facilite l’intégration vitale d’une supervision humaine (« human-in-the-loop ») pour éviter les erreurs coûteuses, tandis que CrewAI excelle dans le déploiement très rapide basé sur des rôles d’agents.
- Salesforce Agentforce / Microsoft Copilot Studio : pour les équipes marketing (sans développeurs), ces solutions « no-code » ou « low-code » offrent un cadre sécurisé pour déployer des agents directement intégrés aux écosystèmes existants, avec des coûts d’usage prévisibles (ex : facturation fixe par conversation).
Adopter l’IA frugale, ce n’est pas renoncer à l’ambition marketing, mais réinventer son rapport à la technologie. Les exemples d’Innovaccer, Microsoft ou Dove le prouvent : une approche sobre génère des gains financiers, environnementaux, et même concurrentiels.
Pour les CMO, la feuille de route est claire :
✅ Prioriser : réserver les LLM aux tâches complexes, et privilégier les SLM pour le reste.
✅ Mesurer : adopter une télémétrie unitaire (coût par lead, par contenu) et anticiper les budgets.
✅ Gouverner : imposer des guardrails, auditer les flux, et briser les silos entre équipes.
✅ Innover : tester des pilotes ciblés, avec des données propres et des workflows optimisés.
La frugalité n’est pas l’ennemi de la performance, elle en est la condition. Dans un monde où les ressources (budgétaires, énergétiques, attentionnelles) se raréfient, les marques qui sauront allier intelligence artificielle et intelligence stratégique seront celles qui l’emporteront. Et si la prochaine révolution marketing était… celle de la sobriété.

Expert en marketing, transformation digitale et management d’équipes, avec plus de 20 ans d’expérience dans des environnements exigeants (ministère des Armées, retail, tech) et variés (B2B et B2C, privé et public). Spécialisé dans le pilotage de stratégies omnicanales, l’optimisation de la performance commerciale (ex : +15 M€ de CA en Drive to Store, +12 % de revenus mobile) la conception de solutions innovantes (produit digital, marketplace, jeux sérieux) et les partenariats stratégiques. Adèpte de la transmission du savoir : 2 blogs, 2 livres, formateur en école de commerce niveau master et coach de thèse professionnelle.
Contrôler et améliorer l’expérience client grâce à l’intelligence artificielle
Découvrez mon « Capstone Project » issu de ma formation pour cadre de l’Université Berkeley ExecEd de Californie :
« Artificial Intelligence: Business Strategies and Applications »



