
L'apprentissage automatique appliqué au SEO : Amplifiez l’analyse de la concurrence
L’apprentissage automatique permet en IA SEO de rechercher et d’analyser ses concurrents. De plus, elle procure des résultats plus précis, ainsi que des statistiques pertinentes et évolutives.
Cet article s’adresse aux marketeurs désireux non pas de se lancer dans l’apprentissage de Python, mais de comprendre les bénéfices du machine learning dans le référencement naturel.
En l’occurrence, comment relever les défis dans la recherche de concurrents SEO ? Comment configurer et former votre modèle d’apprentissage automatique ? Enfin, comment automatiser et déployer l’analyse concurrentielle ?

Pourquoi avons-nous besoin d'apprentissage automatique dans la recherche de concurrents en SEO ?
Tous les professionnels du référencement travaillent sur des marchés concurrentiels. Et pour cause : Un acte d’achat en ligne et/ou en magasin passe quasi-systématiquement par une itération de recherches web ou vocales. Dès lors, il est nécessaire d’analyser les SERP et ses concurrents pour que le site web atteigne un rang plus élevé dans les résultats de recherche. Et ceci dans l’espoir d’obtenir un meilleur taux de click suivi d’un meilleur taux de conversion.
Jusqu’à présent, nous utilisions des feuilles de calcul pour collecter des données à partir des SERP. Elles comprennent bons nombres de colonnes représentant différents niveaux de performances de la concurrence (métriques, KPI et surtout niveaux de performances).
Bien que l’idée sonne « juste », elle n’en demeure pas moins très limitée en raison des possibilités restreintes des feuilles Excel pour effectuer une analyse statistiquement robuste dans le laps de temps requis.
Et si les limites des feuilles de calcul ne suffisaient pas, le paysage de l’écosystème a quant à lui évolué depuis l’apparition de nouveaux facteurs :
- SERP mobiles
- Prise en compte de la vitesse de chargement des pages
- Une expérience de recherche Google beaucoup plus sophistiquée associée à davantage de filtres
- Recherche personnalisée et contextualisée notamment pour les mobinautes
- Mise en œuvre de données structurées
- Frameworks Javascript et autres nouvelles technologies Web
- Présence active dans les Médias sociaux
Ce qui précède n’est en aucun cas une liste exhaustive des tendances. Mais, elle sert à illustrer la gamme toujours croissante de facteurs qui peuvent expliquer l’avantage de vos concurrents les mieux classés sur Google.
Formation de votre modèle d'apprentissage automatique
Vous trouverez ci-dessous un exemple de modèle développé via XGBoost.
Mais, les alternatives que vous pouvez essayer en parallèle aussi sont LightGBM (en particulier pour les ensembles de données beaucoup plus volumineux), RandomForest et Adaboost.
Alors, essayez d’utiliser le code Python suivant pour XGBoost pour l’ensemble de vos données SERP :
Importer les bibliothèques
import xgboost as xgb
import pandas as pd
serps_data = pd.read_csv('serps_data.csv')
Définir les variables du modèle
Vos données SERP avec tout sauf la colonne google_rank
serp_features = serps_data.drop(columns = ['Google_rank'])
Vos données SERPs avec juste la colonne google_rank
rank_actual = serps_data.Google_rank
Instanciation du modèle
serps_model = xgb.XGBRegressor(objective='reg:linear', random_state=1231)
Ajustement du modèle
serps_model.fit(serp_features, rank_actual)
Générer les prédictions du modèle
rank_pred = serps_model.predict(serp_features)
Evaluer la précision du modèle
mse = mean_squared_error(rank_actual, rank_pred)
Notez que ce qui précède est très basique. Car dans un scénario client réel, vous voudriez tester un certain nombre d’algorithmes de modèle sur un échantillon de données d’apprentissage (environ 80 % des données). Puis évaluer (en utilisant les 20 % de données restantes) et sélectionner le meilleur modèle.
Alors, quels secrets ce modèle d’apprentissage automatique peut-il nous révéler ? 😏
Les facteurs de classement les plus prédictifs
Le graphique ci-dessous montre les critères de classement les plus influents pour Google, par ordre décroissant d’importance :
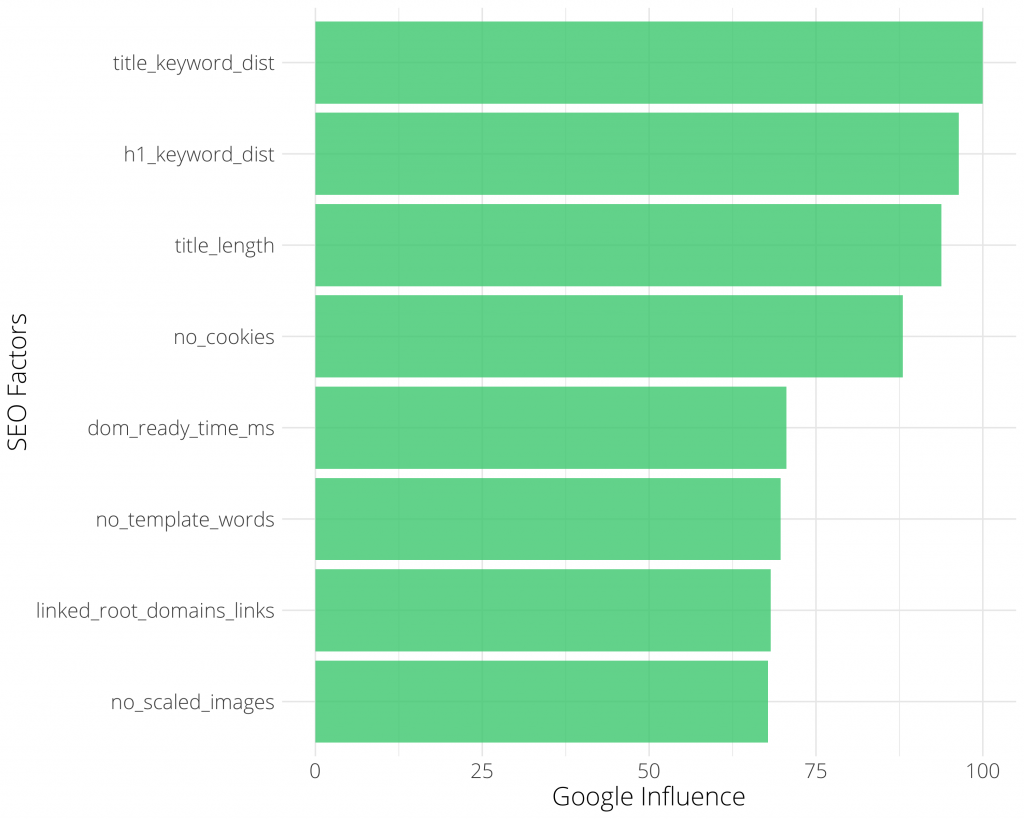
Crédit image : Andreas Voniatis (juin 2021)
Dans ce cas particulier, le critère le plus important (indice 100) est « title_keyword_dist » qui mesure la distance de chaîne entre la balise de titre <title> et le mot-clé cible. Considérez cela comme la pertinence de la balise de titre par rapport au mot-clé.
Pas de surprise pour le praticien du référencement, cependant, l’objectif ici est de fournir des preuves empiriques au public professionnel non expert qui ne comprend pas la nécessité d’optimiser cette fameuse balise de titre. Idem avec le critère « h1_keyword_dist » et la pertinence de la présence des mots clés en balise h1 <h1> avec le mot-clé cible. Ou encore la taille en nombre de caractère de la balise titre <title> que nous allons analyser un peu plus bas dans cet article.
Voici les autres principaux facteurs importants dans ce cas de figure :
no_cookies : Le nombre de cookies
dom_ready_time_ms : une mesure de la vitesse de la page
no_template_words : compte le nombre de mots en dehors du contenu du corps principal
link_root_domains_links : nombre de liens vers la home du site
no_scaled_images : nombre d’images mises à l’échelle qui nécessitent une mise à l’échelle par le navigateur pour être rendues
NB : chaque marché ou industrie est différent, donc ce qui précède n’est pas un résultat général pour l’ensemble du référencement !
Quel est l'impact d'un critère sur le classement organique ?
Dans un autre cas de figure, nous pouvons observer le poids positif ou négatif d’un critère, sur le rang dans les SERP. Dès lors, cela permet de focaliser son attention sur ce qui apportera un bénéfice plus rapide en matière de gain de rang :
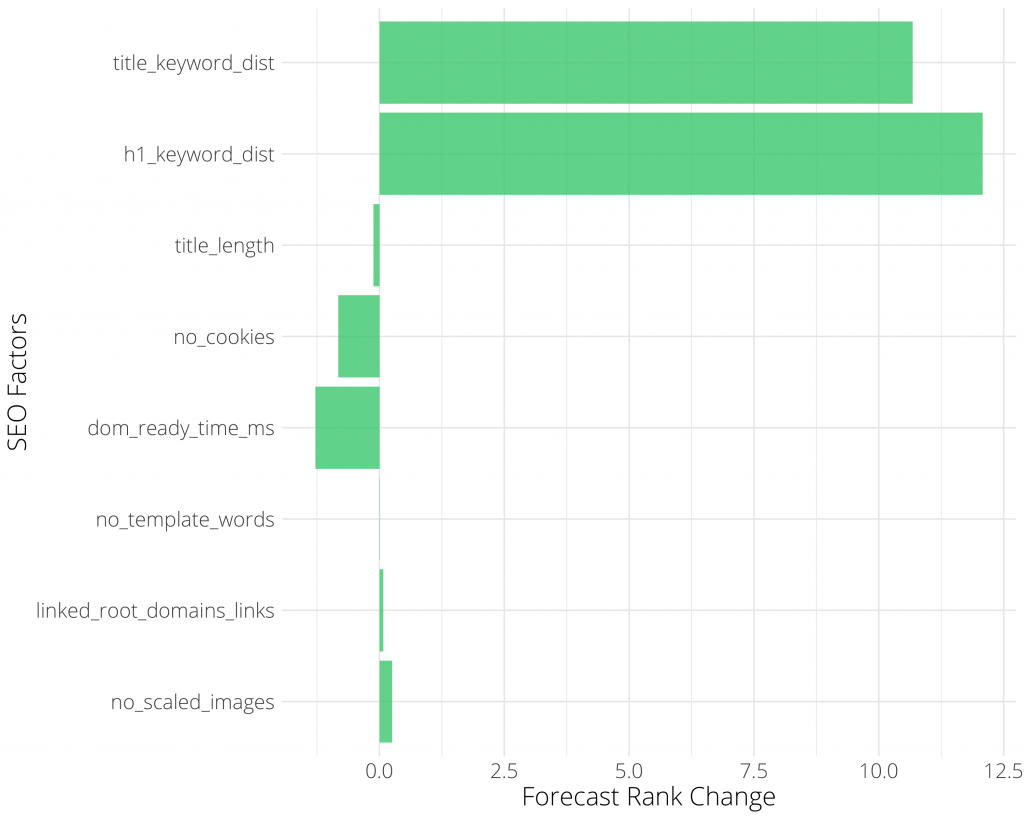
Crédit image : Andreas Voniatis (juin 2021)
Dans le tableau ci-dessus, nous avons une liste de facteurs et le changement de rang pour chaque changement d’unité positif dans ce facteur.
Par exemple, pour chaque augmentation d’unité de la longueur de la méta description de 1 caractère, il y a une diminution correspondante du classement Google de 0,1.
En outre, sorti de son contexte, cela semble ridicule. Cependant, étant donné que la plupart des méta-descriptions sont remplies, cela signifierait qu’un changement d’unité par rapport à la longueur moyenne des méta-descriptions entraînerait alors une diminution du classement dans la recherche Google.
Déterminez vos points de rupture pour un facteur SEO de classement
Vous trouverez ci-dessous un graphique traçant la longueur moyenne des balises de titre pour un secteur différent de celui ci-dessus. Il comprend également une courbe d’ajustement :
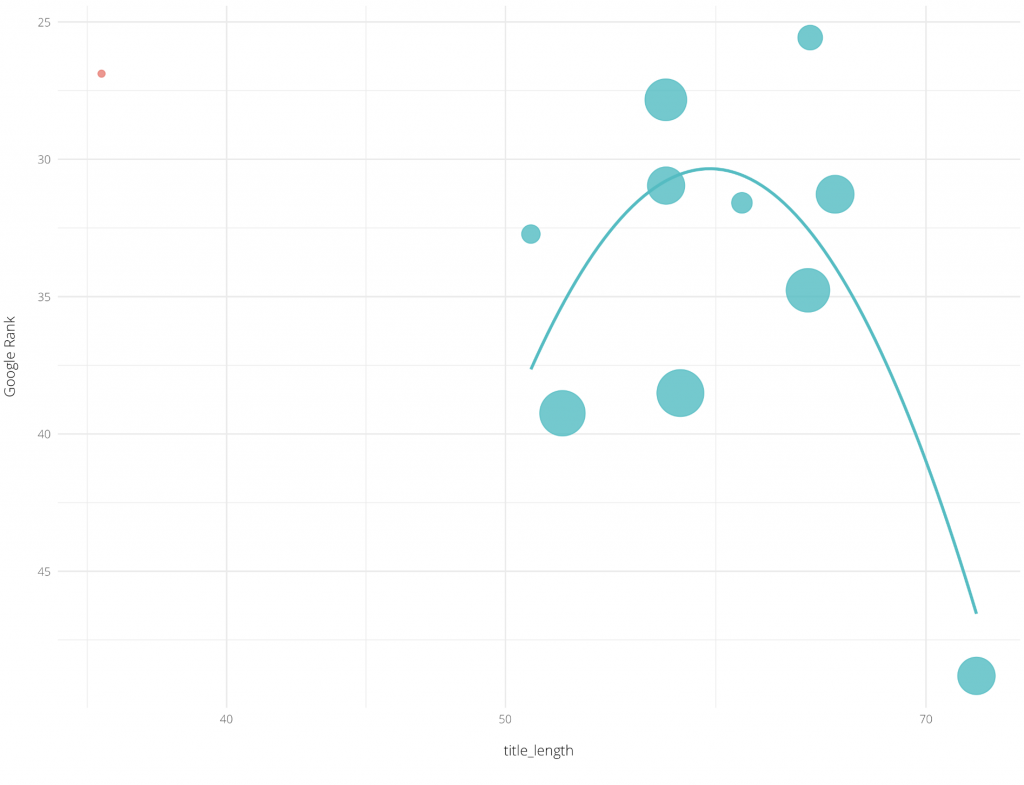
Crédit image : Andreas Voniatis (juin 2021)
La recommandation des meilleures pratiques de référencement consiste à utiliser jusqu’à 70 caractères pour la longueur de la balise de titre. Néanmoins, les données tracées ci-dessus montrent que la longueur optimale réelle dans cette industrie est de 60 caractères. Il est donc important d’adapter son dispositif en conséquence.
Grâce à l'apprentissage automatique, nous sommes non seulement en mesure de mettre en évidence les facteurs les plus importants pour améliorer le classement, mais nous pouvons également affiner les spécificités et les valeurs de chaque facteur
@ia4marketing Tweet
Automatiser votre analyse de la concurrence SEO avec l'apprentissage automatique
Les analyses décrites ci-dessus sont faites sur la base d’une photo prise à un instant t. Elles démontrent les bienfaits de l’approche relative au machine learning, en insights permettant de prendre les bonnes décisions de gestion. Mais, pour rester performant dans la durée vis-à-vis de vos concurrents, il est nécessaire d’automatiser le processus à l’aide d’un ETL : Extract, Transform, Load.
- Extrait – Appel quotidien de vos API d’outils de référencement et de leurs données relatives
- Transformer – Nettoyage et analyse de vos données à l’aide du machine learning
- Charger – Déposer le résultat final dans votre entrepôt de données et déployer des tableaux de bord comme dans Google Data Studio
Ce flux de collecte et d’analyse de données permet une analyse en temps réel de ce qui se passe dans les SERP. Et il permet de comprendre les facteurs clés des mouvements de la concurrence.
Pour créer votre propre ETL, vous pouvez disposer d’une infrastructure cloud comme Amazon Web Services (AWS) ou Google Cloud Platform (GCP).

Expert en marketing, transformation digitale et management d’équipes, avec plus de 20 ans d’expérience dans des environnements exigeants (ministère des Armées, retail, tech) et variés (B2B et B2C, privé et public). Spécialisé dans le pilotage de stratégies omnicanales, l’optimisation de la performance commerciale (ex : +15 M€ de CA en Drive to Store, +12 % de revenus mobile) la conception de solutions innovantes (produit digital, marketplace, jeux sérieux) et les partenariats stratégiques. Adèpte de la transmission du savoir : 2 blogs, 2 livres, formateur en école de commerce niveau master et coach de thèse professionnelle.
Contrôler et améliorer l’expérience client grâce à l’intelligence artificielle
Découvrez mon « Capstone Project » issu de ma formation pour cadre de l’Université Berkeley ExecEd de Californie :
« Artificial Intelligence: Business Strategies and Applications »




Un commentaire