
7 projets à haut potentiel de vision par ordinateur
La quête de la capacité des ordinateurs et des robots à réellement « voir » et « comprendre » l’univers qui les entoure a été une force motrice du développement de l’intelligence artificielle ces dernières années. J’en parle dès mon premier article sur ce blog. Et plus récemment dans mon Capstone Project issu de ma formation pour cadre de l’Université Berkeley ExecEd de Californie : Contrôler et améliorer l’expérience client grâce à l’intelligence artificielle.
De plus, je suis convaincu que ce domaine est un pivot important dans l’adoption par les organisations de l’automatisation à grande échelle.
En effet, la vision par ordinateur est la solution technologique sur laquelle nous nous appuyons sur de très nombreux cas d’usages. Alors dans cet article inspiré du blog d’Omdena, nous allons lister 7 projets à haut potentiel de vision par ordinateur. De plus, j’ajoute qu’ils sont tous accompagnés de leur projet open-source disponibles en ligne via GitHub.
Quelles sont les usages de la vision par ordinateur ?
La vision par ordinateur (Computer vision en anglais) est un terme général. Il recouvre de très nombreux projets faisant appel à des réseaux neuronaux profonds pour développer des capacités de vision semblables à celles des humains. D’ailleurs, aujourd’hui, la vision par ordinateur a un immense potentiel dans les applications du monde réel. ce qui est notamment le cas dans la santé, le transport, l’agriculture, l’industrie ou encore le commerce de détail, la construction, le sport, et bien entendu la finance et les assurances… Certains cas d’utilisation impliquent des projets de vision par ordinateur qui ont un impact positif sur le monde pour le rendre meilleur.
Voici 5 façons dont la vision par ordinateur façonnera l’avenir :

(Source https://cachengo.com )
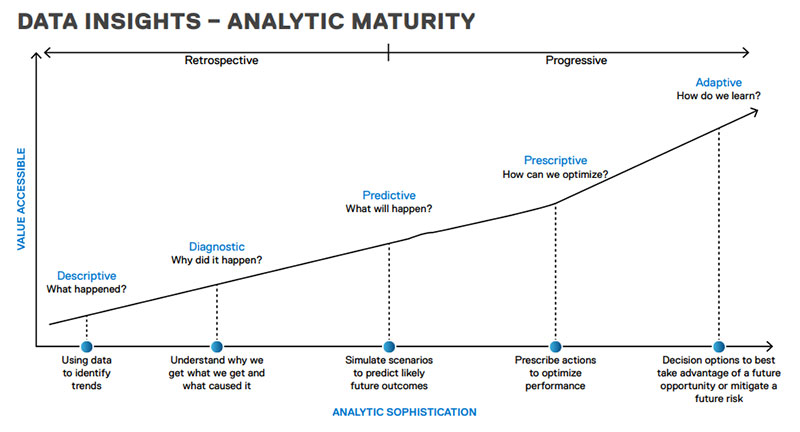
Mais il existe aussi une autre façon de voir les choses, grâce à la courbe de maturité de l’analytique. En effet, au cours des dernières années, de nombreuses organisations ont franchis le point-break. Car jusqu’ici elles utilisaient la vision par ordinateur comme moyen d’obtenir des résultats descriptifs et diagnostiques. Désormais elles adoptent une approche plus prédictive et adaptative. Ainsi, les modèles aident à prévoir les résultats probables afin de parier sur l’avenir tout en minimisant les risques.
Comment fonctionne la vision par ordinateur ?
La vision par ordinateur fonctionne en analysant des quantités massives de données. Et ce, jusqu’à ce qu’elle reconnaisse des distinctions et reconnaisse les images correctement. Alors, grâce à la vision par ordinateur, nous pouvons entraîner un ordinateur à faire la différence entre un bon pneu de voiture et un pneu défectueux. En fait, il « suffit » de lui fournir de nombreuses photos de ces types de pneus. Finalement, l’ordinateur apprendra la différence et reconnaîtra un bon pneu, versus celui présentant des défauts.
En sommes, voici les quelques technologies qui permettent d’obtenir le résultat souhaité en matière de vision par ordinateur :
1. Un type d’apprentissage automatique appelé « apprentissage profond ».
L’apprentissage automatique utilise des modèles algorithmiques pour apprendre à l’ordinateur le contexte des données visuelles. Ce qui permet de différencier une image d’une autre. Les algorithmes permettent l’auto-apprentissage des machines sans programmation spécifique pour reconnaître une image.
2. Réseau neuronal convolutif (CNN)
Un CNN est utilisé pour comprendre des images uniques. Tandis qu’un réseau neuronal récurrent (RNN) est utilisé pour la vidéo afin d’aider les ordinateurs à comprendre les relations entre les images d’une série de trames. Un réseau neuronal récurrent aide le modèle d’apprentissage automatique à examiner plus en profondeur les images. Il les décompose en pixels et les étiquète. Dès lors, ces étiquettes sont utilisées pour effectuer des convolutions et faire des prédictions sur ce qui est « vu ». Le réseau neuronal effectue de multiples itérations, exécute des convolutions et vérifie l’exactitude de ses prédictions. Ces opérations sont menées jusqu’à ce qu’il parvienne à une prédiction correcte (voir des images spécifiques comme les humains).
Voici les 7 projets open-source à haut potentiel de vision par ordinateur :
1. Santé : Classification des pathologies
La quantité de données que les pathologistes doivent analyser en une journée est massive et difficile. Or, les algorithmes d’apprentissage profond peuvent identifier des modèles dans de grandes quantités de données. La tomographie par cohérence optique (OCT) utilise des ondes lumineuses pour regarder à l’intérieur d’un corps humain vivant. Ainsi, elle peut détecter diverses maladies chez les humains, les plantes et les animaux.
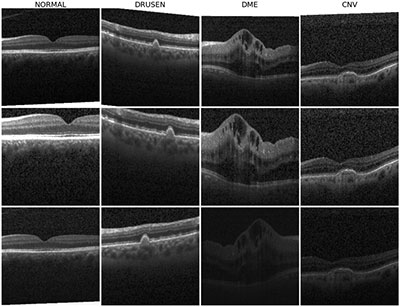
(Source https://neptune.ai/)
D’ailleurs, il est possible d’évaluer des problèmes tels que l’amincissement de la peau, les ruptures de vaisseaux sanguins, les maladies cardiaques et de nombreux autres problèmes médicaux.
(Source https://neptune.ai/)
D’ailleurs, il est possible d’évaluer des problèmes tels que l’amincissement de la peau, les ruptures de vaisseaux sanguins, les maladies cardiaques et de nombreux autres problèmes médicaux.
1. Santé : Classification des pathologies
La quantité de données que les pathologistes doivent analyser en une journée est massive et difficile. Or, les algorithmes d’apprentissage profond peuvent identifier des modèles dans de grandes quantités de données. La tomographie par cohérence optique (OCT) utilise des ondes lumineuses pour regarder à l’intérieur d’un corps humain vivant. Ainsi, elle peut détecter diverses maladies chez les humains, les plantes et les animaux.
2. Media : Colorisation automatique d'images
La colorisation d’images consiste à ajouter des couleurs plausibles à des photographies ou des vidéos monochromes. En fait, elle les rend visuellement acceptables et perceptiblement significatives pour convaincre le spectateur de leur authenticité.
Or, la couleur est un élément très important de la représentation visuelle. Mais les photos en noir et blanc ne permettent pas d’imaginer pleinement la scène représentée. De plus, les objets peuvent avoir des couleurs différentes. Soit en raison de la perspective, de l’éclairage ou de nombreux autres facteurs. Ainsi, il existe de nombreuses façons d’attribuer des couleurs aux pixels d’une image.
En outre, la connaissance des couleurs d’origine des vieilles photos est très souvent indisponible. Ainsi, l’opération de colorisation automatique est très difficile. Et il n’y a pas de solution unique à ce problème. Néanmoins, le but de la colorisation est de tromper l’observateur, de lui faire croire à l’authenticité de l’image colorisée. Et non de reconstruire la couleur avec précision.

(Source https://github.com/ericsujw/)
Les précédentes méthodes de colorisation d’images s’appuient sur le réseau neuronal profond. Elles font correspondre directement les images d’entrée en niveaux de gris à des sorties couleur plausibles. Dans un premier temps, ces méthodes basées sur l’apprentissage ont montré des performances impressionnantes. Mais, elles échouent généralement sur les images d’entrée qui contiennent plusieurs objets. En fait, la cause principale est que les modèles existants effectuent l’apprentissage et la colorisation sur l’image entière. Et en l’absence d’une séparation claire entre la figure et le fond, ces modèles ne peuvent pas localiser efficacement et apprendre une sémantique significative au niveau de l’objet.
Nouvelle méthode de colorisation automatique d'images
Dans ce projet open-source, l’auteur propose une méthode pour réaliser la colorisation en fonction de l’instance. D’une part, il exploite un détecteur d’objets standard pour obtenir des images d’objets recadrées. Et ensuite, il utilise un réseau de colorisation d’instance pour extraire des caractéristiques au niveau de l’objet. Puis il prédit les couleurs finales sur l’ensemble de l’image.
(Source https://github.com/ericsujw/)
Les précédentes méthodes de colorisation d’images s’appuient sur le réseau neuronal profond. Elles font correspondre directement les images d’entrée en niveaux de gris à des sorties couleur plausibles. Dans un premier temps, ces méthodes basées sur l’apprentissage ont montré des performances impressionnantes. Mais, elles échouent généralement sur les images d’entrée qui contiennent plusieurs objets. En fait, la cause principale est que les modèles existants effectuent l’apprentissage et la colorisation sur l’image entière. Et en l’absence d’une séparation claire entre la figure et le fond, ces modèles ne peuvent pas localiser efficacement et apprendre une sémantique significative au niveau de l’objet.
Nouvelle méthode de colorisation automatique d'images
Dans ce projet open-source, l’auteur propose une méthode pour réaliser la colorisation en fonction de l’instance. D’une part, il exploite un détecteur d’objets standard pour obtenir des images d’objets recadrées. Et ensuite, il utilise un réseau de colorisation d’instance pour extraire des caractéristiques au niveau de l’objet. Puis il prédit les couleurs finales sur l’ensemble de l’image.
2. Media : Colorisation automatique d'images
La colorisation d’images consiste à ajouter des couleurs plausibles à des photographies ou des vidéos monochromes. En fait, elle les rend visuellement acceptables et perceptiblement significatives pour convaincre le spectateur de leur authenticité.
Or, la couleur est un élément très important de la représentation visuelle. Mais les photos en noir et blanc ne permettent pas d’imaginer pleinement la scène représentée. De plus, les objets peuvent avoir des couleurs différentes. Soit en raison de la perspective, de l’éclairage ou de nombreux autres facteurs. Ainsi, il existe de nombreuses façons d’attribuer des couleurs aux pixels d’une image.
En outre, la connaissance des couleurs d’origine des vieilles photos est très souvent indisponible. Ainsi, l’opération de colorisation automatique est très difficile. Et il n’y a pas de solution unique à ce problème. Néanmoins, le but de la colorisation est de tromper l’observateur, de lui faire croire à l’authenticité de l’image colorisée. Et non de reconstruire la couleur avec précision.
3. Langage : Reconnaissance de texte (OCR)
Lors de l’utilisation de la reconnaissance de texte à l’aide d’OCR (Optical Character Recognition) sur une image, nous identifions chaque lettre et la convertissons en texte. Cette solution est optimale pour quiconque cherche à extraire des informations d’une image ou d’une vidéo et à les convertir en données textuelles.
Tesseract est une application open-source soutenue par Google qui peut reconnaître du texte dans plus de 100 langues.

On peut également entraîner cette application à identifier de nombreuses autres langues.
Des applications comme le scanner de PDF et Google Lens utilisent l’OCR.
On peut également entraîner cette application à identifier de nombreuses autres langues.
Des applications comme le scanner de PDF et Google Lens utilisent l’OCR.
3. Langage : Reconnaissance de texte (OCR)
Lors de l’utilisation de la reconnaissance de texte à l’aide d’OCR (Optical Character Recognition) sur une image, nous identifions chaque lettre et la convertissons en texte. Cette solution est optimale pour quiconque cherche à extraire des informations d’une image ou d’une vidéo et à les convertir en données textuelles.
Tesseract est une application open-source soutenue par Google qui peut reconnaître du texte dans plus de 100 langues.
4. Media : Animation d'images
Avec un modèle en mouvement au premier plan, ce projet permet d’animer des visages ou des personnages à partir de vidéos et d’images. Ici, le modèle prend une vidéo d’un discours et fait correspondre son mouvement à des images statiques pour donner une apparence réaliste. Le chargement du modèle utilise Python, et le code source est disponible dans le dépôt GitHub.

(Source https://github.com/snap-research/)
Le modèle de mouvement au premier plan (FOMM) se compose de deux parties principales :
- L’estimation du mouvement et la génération d’images. Il s’agit d’une estimation grossière du mouvement. Elle est modélisée comme des mouvements épars entre des parties d’objet séparées.
- Et un mouvement dense, produisant un flux optique pour l’image entière.
(Source https://github.com/snap-research/)
Le modèle de mouvement au premier plan (FOMM) se compose de deux parties principales :
- L’estimation du mouvement et la génération d’images. Il s’agit d’une estimation grossière du mouvement. Elle est modélisée comme des mouvements épars entre des parties d’objet séparées.
- Et un mouvement dense, produisant un flux optique pour l’image entière.
4. Media : Animation d'images
Avec un modèle en mouvement au premier plan, ce projet permet d’animer des visages ou des personnages à partir de vidéos et d’images. Ici, le modèle prend une vidéo d’un discours et fait correspondre son mouvement à des images statiques pour donner une apparence réaliste. Le chargement du modèle utilise Python, et le code source est disponible dans le dépôt GitHub.
5. Media : Stylisation d'un visage
La stylisation d’images, ou d’un visage en l’occurrence ici, requiert la capture des détails stylistiques importants, tels que la forme des yeux, ou encore, l’audace des lignes. Mais ces détails sont particulièrement difficiles à apprendre pour un modèle, surtout dans un contexte de données limitées.
Dans le projet « JoJoGAN », vous pourrez découvrir le mappeur de style, qui applique certains styles fixes aux images d’entrée, notamment des visages.
D’une part, il utilise les propriétés de mélange de styles de StyleGAN pour produire des ensembles de données de styles appariés à partir d’un seul exemple.

(Source https://github.com/mchong6/JoJoGAN)
D’autre part, sur ces données appariées, il exécute le mappage de styles par inversion GAN suivie par le StyleGAN affiné.
JoJoGAN peut utiliser avec succès des références de style extrêmes (par exemple, des visages d’animaux). Et l’on peut contrôler les aspects du style utilisés et la quantité de style appliquée comme résultat. De plus, l’algorithme produit une résolution de haute qualité.
(Source https://github.com/mchong6/JoJoGAN)
D’autre part, sur ces données appariées, il exécute le mappage de styles par inversion GAN suivie par le StyleGAN affiné.
JoJoGAN peut utiliser avec succès des références de style extrêmes (par exemple, des visages d’animaux). Et l’on peut contrôler les aspects du style utilisés et la quantité de style appliquée comme résultat. De plus, l’algorithme produit une résolution de haute qualité.
5. Media : Stylisation d'un visage
La stylisation d’images, ou d’un visage en l’occurrence ici, requiert la capture des détails stylistiques importants, tels que la forme des yeux, ou encore, l’audace des lignes. Mais ces détails sont particulièrement difficiles à apprendre pour un modèle, surtout dans un contexte de données limitées.
Dans le projet « JoJoGAN », vous pourrez découvrir le mappeur de style, qui applique certains styles fixes aux images d’entrée, notamment des visages.
D’une part, il utilise les propriétés de mélange de styles de StyleGAN pour produire des ensembles de données de styles appariés à partir d’un seul exemple.
6. Media : Restauration d'images
D’une part, la restauration d’images est un problème de vision de bas niveau qui existe depuis longtemps. Et qui consiste à restaurer des images HQ à partir d’images LQ (images réduites, bruitées ou compressées).
On notamment peut restaurer des vidéos et des images qui sont floues.
D’autre part, la restauration vidéo (par exemple, la super-résolution vidéo) vise à restaurer des images de haute qualité à partir d’images de basse qualité.

(Source https://github.com/JingyunLiang/VRT)
Alors, contrairement à la restauration d’une seule image, la restauration vidéo nécessite généralement l’utilisation d’informations temporelles provenant de plusieurs images vidéo adjacentes. Mais elles sont généralement mal alignées. Alors, le transformateur de restauration vidéo (VRT) possède, ici dans ce projet disponible sur GitHub, à la fois :
- des capacités de prédiction de trames parallèles
- et des capacités de modélisation de la dépendance temporelle à longue portée.
(Source https://github.com/JingyunLiang/VRT)
Alors, contrairement à la restauration d’une seule image, la restauration vidéo nécessite généralement l’utilisation d’informations temporelles provenant de plusieurs images vidéo adjacentes. Mais elles sont généralement mal alignées. Alors, le transformateur de restauration vidéo (VRT) possède, ici dans ce projet disponible sur GitHub, à la fois :
- des capacités de prédiction de trames parallèles
- et des capacités de modélisation de la dépendance temporelle à longue portée.
6. Media : Restauration d'images
D’une part, la restauration d’images est un problème de vision de bas niveau qui existe depuis longtemps. Et qui consiste à restaurer des images HQ à partir d’images LQ (images réduites, bruitées ou compressées).
On notamment peut restaurer des vidéos et des images qui sont floues.
D’autre part, la restauration vidéo (par exemple, la super-résolution vidéo) vise à restaurer des images de haute qualité à partir d’images de basse qualité.
7. Media : Génération de schéma de scène
Des chercheurs néerlandais ont mis en libre accès RelTR, une méthode en une étape qui, par le biais de l’apparence visuelle uniquement, ne permet d’obtenir que des relations dignes d’intérêt entre les objets d’une image.
Les différents objets d’une même scène sont légèrement liés les uns aux autres. Cependant, seul un nombre limité de ces relations sont dignes d’intérêt.
La génération du graphe de la scène est considérée comme un problème de prédiction d’ensemble.
(Source https://github.com/yrcong/RelTR)
La solution proposée est un modèle de génération de graphe de scène de bout en bout, RelTR, ayant une architecture d’encodeur-décodeur. RelTR est une méthode en une étape qui prédit un ensemble de relations directement en utilisant uniquement l’apparence visuelle. Elle ne combine pas les entités et n’étiquette pas tous les prédicats possibles.
(Source https://github.com/yrcong/RelTR)
La solution proposée est un modèle de génération de graphe de scène de bout en bout, RelTR, ayant une architecture d’encodeur-décodeur. RelTR est une méthode en une étape qui prédit un ensemble de relations directement en utilisant uniquement l’apparence visuelle. Elle ne combine pas les entités et n’étiquette pas tous les prédicats possibles.
7. Media : Génération de schéma de scène
Des chercheurs néerlandais ont mis en libre accès RelTR, une méthode en une étape qui, par le biais de l’apparence visuelle uniquement, ne permet d’obtenir que des relations dignes d’intérêt entre les objets d’une image.
Les différents objets d’une même scène sont légèrement liés les uns aux autres. Cependant, seul un nombre limité de ces relations sont dignes d’intérêt.
La génération du graphe de la scène est considérée comme un problème de prédiction d’ensemble.

Expert en marketing, transformation digitale et management d’équipes, avec plus de 20 ans d’expérience dans des environnements exigeants (ministère des Armées, retail, tech) et variés (B2B et B2C, privé et public). Spécialisé dans le pilotage de stratégies omnicanales, l’optimisation de la performance commerciale (ex : +15 M€ de CA en Drive to Store, +12 % de revenus mobile) la conception de solutions innovantes (produit digital, marketplace, jeux sérieux) et les partenariats stratégiques. Adèpte de la transmission du savoir : 2 blogs, 2 livres, formateur en école de commerce niveau master et coach de thèse professionnelle.
Contrôler et améliorer l’expérience client grâce à l’intelligence artificielle
Découvrez mon « Capstone Project » issu de ma formation pour cadre de l’Université Berkeley ExecEd de Californie :
« Artificial Intelligence: Business Strategies and Applications »




Un commentaire