
L’Intelligence Artificielle et sa soutenabilité
Qu’est-ce que l’IA ?
Qualifiée de nouvelle électricité du 21ème siècle par Andrew Ng, professeur expert à Stanford, l’intelligence artificielle (IA) est annoncée comme la 4ème révolution industrielle.

Définition
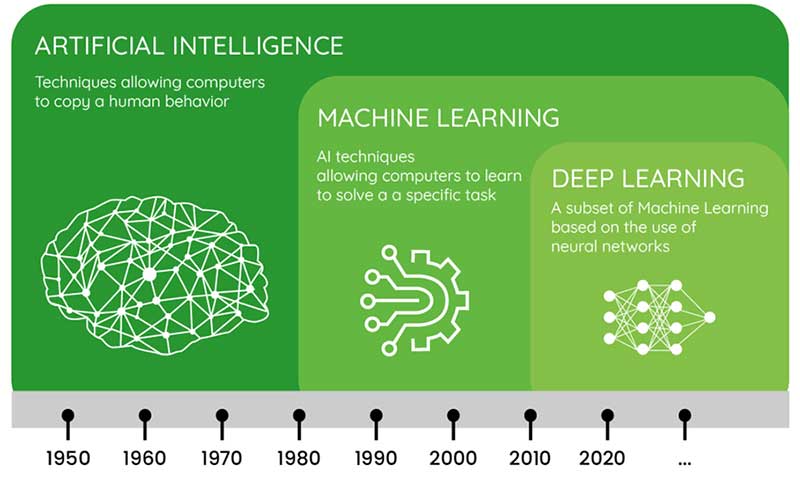
L’intelligence artificielle relève de technologies informatiques permettant à des machines d’apprendre et de réaliser des tâches traditionnellement dévolues à l’intelligence humaine. Cette discipline scientifique est « jeune » de soixante-six ans car c’est en 1956 qu’elle a été officialisée lors de la conférence organisée par John McCarthy (Dartmouth) et Marvin Minsky (Princeton) au Dartmouth College – États-Unis. L’émergence du Machine Learning (apprentissage automatique), un sous domaine de l’intelligence artificielle, a lieu dans les années quatre-vingt-dix et entraine le développement d’algorithmes qui permettent de réaliser des prédictions à partir de données tout en s’améliorant au fil du temps.
IA et Sciences des données (Source dilepix)
Portée par le big data, l’explosion de la puissance de calcul (en lien avec la loi de Moore) et le deep learning (apprentissage profond), l’intelligence artificielle connaît depuis le début des année 2000 un intérêt croissant qui ne faiblit pas. Toutes les applications d’intelligence d’artificielle relèvent à ce jour de ce que l’on appelle l’IA faible (ou IA étroite) dédiée à la résolution de tâches spécifiques comme la reconnaissance d’images ou le traitement du langage naturel. Une IA forte (ou IA générale), dotée d’esprit, de sensibilité, de conscience relève encore de la science-fiction.
IA connexionniste et IA symbolique
Les rivalités entre ces deux courants de l’IA existent depuis le début de l’histoire de l’intelligence artificielle. Basée sur des règles et des connaissances, l’IA symbolique permet l’explicabilité des algorithmes ce qui est beaucoup moins évident pour l’IA connexionniste basée sur des réseaux de neurones artificiels. Alors que les modèles de deep learning nécessitent de grand volume de données pour pouvoir effectuer des prédictions, l’IA symbolique est très frugale en matière de données. En réalité, chaque approche présente des atouts et des limites et l’avenir semble s’orienter vers l’IA neuro-symbolique combinant ainsi le meilleur des deux mondes.
Le machine learning
Sous domaine de l’intelligence artificielle, le Machine Learning (Apprentissage Automatique) comprend de nombreux algorithmes pour créer à partir des données des modèles dont les performances s’améliorent au fil de leur entrainement. Le Machine Learning est divisé en trois grandes catégories : l’apprentissage supervisé, l’apprentissage non supervisé, l’apprentissage par renforcement. Toutes les formes de Machine Learning s’appuient sur des statistiques et des probabilités qu’un événement ou une action ne produise ou non.
Le Deep Learning
- Au début le perceptron
Inspiré du neurone biologique, le perceptron est un algorithme d’apprentissage supervisé parmi les plus simples pour la classification binaire (0 ou 1). Le tout premier modèle mathématique d’un neurone artificiel fut proposé par les américains Warren S. McCulloch et Walter H. Pitts en 1943 mais c’est le psychologue américain Frank Rosenblatt qui a mis au point le perceptron en 1957.
- Les réseaux de neurones
On retrouve des réseaux de neurones perceptron simple couche qui comprennent une couche d’entrée (Input layer) qui capte les données d’entrée et les transmets après pondération et traitement à la seconde couche cachée (Hidden layer) qui en fait de même vers la couche de sortie (Output layer) pour formuler une réponse de sortie. Il s’agit d’un réseau à propagation directe ou avant (feedforward). La limitation du perceptron simple couche vient du fait qu’il ne peut que séparer des groupes séparables linéairement. L’ajout de couches intermédiaires pour former un perceptron multicouche permet de surmonter ce problème.
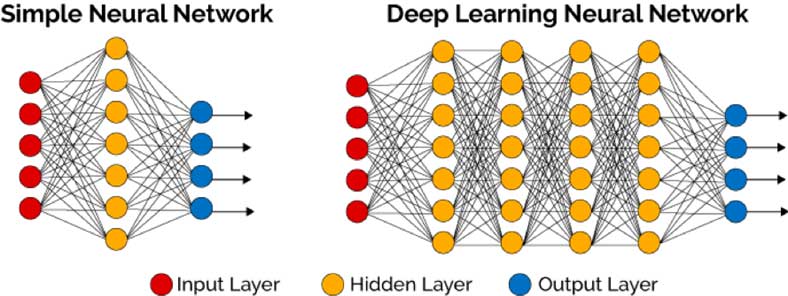
Réseaux de neurones simple couche et multicouche (Source : Sufyan T. Faraj Al-Janabi)
Pour ce type de modèle, le nombre de paramètres devient très vite très important : nombre de couches, nombre de neurones associés, nombre de poids synaptiques et autres paramètres associés à chaque neurone, … De plus, comme l’entrainement des réseaux de neurones nécessite de nombreuses données, l’apprentissage d’un modèle de Deep Learning peut nécessiter plusieurs jours voire plusieurs semaines sur du matériel dédié spécifiquement.
- De modèles de plus en plus complexes
Réseaux de neurones convolutionnels – CNN (Convolutional Neural Networks)
Les réseaux de neurones convolutionnels sont très efficaces pour classer des images et identifier des objets.
Plusieurs centaines de milliers d’images annotées sont nécessaires pour entrainer ce type de réseau, ce qui est assez couteux en termes de matériel, d’expertise et de temps de calcul (plusieurs semaines).
Réseaux de neurones récurrents – RNN (Recurrent Neural Networks)
Les réseaux de neurones récurrents sont surtout utilisés pour le traitement du langage naturel et la reconnaissance vocale. Ce type réseau utilise les résultats précédents comme entrées supplémentaires et peuvent traiter des données séquentielles. Ils disposent ainsi d’une mémoire à court terme qui leur permet de retenir les mots précédents dans une phrase mais il ne leur est pas possible d’accéder à des informations d’un passé lointain. Le temps de calcul est long et ils peuvent être difficiles à entrainer en raison de la disparition du gradient (Gradient Vanishing).
Réseaux LSTM, GRU et Transformer
Les réseaux LSTM (Long Short-Term Memory), GRU (Gated Recurrent Unit) et les Transformer qui sont des modèles à séquences plus complexes que les réseaux RNN. Ils ont permis d’obtenir de très bons résultats dans la reconnaissance de texte, de la parole, la traduction linguistique mais également la génération de texte ou de musique. Si la précision s’améliore, l’entrainement de ces modèles est souvent difficile pour des raisons de capacité mémoire liée au très grand nombre de paramètres et d’opérations nécessaires
L’IA distribuée
Parmi les différentes approches de l’intelligence artificielle, l’IA distribuée s’appuie sur la coopération de nombreux agents ou nœuds d’apprentissage autonomes qui agissent collectivement mais de manière décentralisée (systèmes multi-agents). L’idée est ici de prendre en compte une intelligence collective plutôt qu’individuelle. L’intelligence artificielle distribuée peut rassembler plusieurs réseaux de neurones interconnectés et permet ainsi de réaliser des tâches complexes (gestion de véhicules autonomes ou semi-autonomes par exemple) pouvant nécessiter de très gros volumes de données.
L’écosystème Big Data et IA
Les développements fulgurants de l’intelligence artificielle ont été rendus possibles par le Big Data (ou la capacité de stocker et de gérer de très gros volumes de données), la montée exponentielle de puissance de calcul et le développement des algorithmes de machine learning.

- Le Big data
Le Big Data a été rendu possible par l’explosion du volume de données, la démocratisation de l’accès à l’information, la baisse des coûts matériels, une vague d’innovation sans précédent. Le volume mondial de données a été estimé à 47 zettaoctets (mille milliards de téraoctet) en 2020 et devrait atteindre 175 zettaoctets en 2025. Ce volume serait ensuite multiplié par 3,5 tous les 5 ans pour atteindre 2142 zettaoctets. Les données sont regroupées en deux catégories : les « données structurées », généralement des bases de données relationnelles (SQL, NewSQL) regroupant des chiffres et des nombres et les « données non structurées » qui relèvent du texte et du multimédia.
- Les processeurs
Il existe différents types de processeurs (CPU, GPU, TPU, FPGA, NPU, …), leur conception dépend des tâches à réaliser et certains processeurs ont été spécialisés afin améliorer les temps de traitement des applications d’IA.
CPU (Central Processing Unit)
Souvent appelé le « cerveau » de l’ordinateur, le CPU (Central Processing Unit) est composé de millions de transistors gravés lors de l’usinage et peut comporter plusieurs cœurs de traitement. Il est chargé de l’exécution des instructions des programmes.
Les grands constructeurs de processeurs que sont Intel et AMD travaillent à réduire la consommation électrique des CPU en optimisant leur architecture interne. En mai 2021, IBM a annoncé avoir mis au point un processeur de la taille d’un ongle gravé à 2 nanomètres et qui comporterait 50 milliards de transistors. Les performances seraient plus élevées que pour une puce gravée à 7 nanomètres pour une consommation d’énergie inférieur de 75%.
GPU (Graphics Processing Unit)
En 2006, l’université de Stanford découvre que les GPU, des accélérateurs graphiques avec un très grand nombre de cœurs mais plus simples que les cœurs des processeurs classiques, offrent de meilleures performances par watt. Alors qu’un CPU est limité à quelques dizaines de cœurs, le GPU qui peut en comporter plusieurs dizaines de milliers s’avère donc adapté au calcul intensif grâce à la parallélisation massive de tâches. Agissant comme des microprocesseurs spécialisés, les GPU ont permis le développement du deep learning. La consommation d’énergie n’est cependant pas en reste car l’enveloppe thermique ou le TDP (Thermal Design Power) du GPU H100 de Nvidia, qui caractérise la dissipation d’énergie nécessaire pour fonctionner, est évaluée à 700 watts. Le TDP d’un ordinateur portable est généralement compris entre 15 et 25 watts. Pour le Machine Learning, il est généralement préférable de mobiliser le processeur central (CPU) alors pour le Deep Learning mieux vaut solliciter le processeur graphique (GPU).
TPU (Tensor Processing Unit)
Les TPU ont été conçus entièrement par Google pour des applications spécifiques. Ils relèvent des ASIC (Application Specific Integrated Circuit) des circuits intégrés à application spécifique. Utilisés dans leurs infrastructures depuis 2015, ils n’ont été dévoilés au grand public qu’à partir de 2018. Disponibles en version cloud, les TPU sont très rapides pour effectuer des calculs vectoriels et matriciels denses afin d’accélérer l’entrainement et l’inférence des modèles d’IA. En mai 2021, Google a annoncé que la quatrième génération de TPU (TPUv4) qui serait deux fois plus performante que la précédente.
FPGA (Field Programmable Gate Array)
Les FPGA ou réseaux de portes programmables en français constituent une autre option d’accélération matérielle. Contrairement aux CPU, ces circuits sont composés de cellules qui peuvent être reprogrammées après fabrication. Ils peuvent donc être configurés très finement pour différents types de modèles de Machine Learning et permettent d’obtenir de faibles requêtes d’inférence en temps réel. Depuis 2017, Microsoft a intégré ces composants dans ses datacenters Azure.
NPU (Neural Processing Unit)
Les processeurs neuromorphiques ou NPU s’inspirent du fonctionnement du cerveau et pourraient devenir l’avenir en matière d’économie d’énergie. C’est d’ailleurs l’enjeu pour intégrer l’IA sur des dispositifs embarqués. L’approche repose sur l’intégration directe de la mémoire aux unités de calcul et à la communication des nombreux cœurs entre eux comme le font les synapses. Le 30 septembre 2021, Intel a dévoilé sa puce Loihi2 qui contient un million de neurones artificiels, soit 8 fois plus que la version précédente (Loihi1) et est aussi dix fois plus rapide. Destinées aux activités de recherche, ces puces sont disponibles en accès sur le cloud. Cependant les algorithmes et les langages de programmation devront probablement être repensés pour profiter de tout le potentiel qu’elles représentent.
Puces photoniques
Encore du domaine de la recherche, les puces photoniques utilisent des photons pour transporter de l’information. Ces dernières ont l’avantage de ne pas créer d’interférence magnétique, ni de créer de la chaleur. L’intérêt est d’accéder à des performances potentiellement cinquante fois supérieures à celle des circuits électriques actuels. Le processeur photonique PACE lancé par la société chinoise Xizhi Technlogy en décembre 2021 promet même d’être cent fois plus rapide que les GPU actuels.
- L’ordinateur quantique
Alors que les données de l’informatique classique sont codées en « bit » (des zéros ou des uns), l’ordinateur quantique utilise le « qubit » (bit quantique) qui est une combinaison linéaire où le qubit peut prendre la valeur zéro ou un mais aussi les deux ensemble. Ces propriétés permettraient de réaliser des calculs en parallèle de manière simultanée et non plus de manière séquentielle, des quantités phénoménales de données pourraient ainsi être traitées dans des temps extrêmement faibles. Cela relève encore du défi pour les équipes de recherche.
- L'edge computing
Alternative au cloud computing, l’edge computing est une architecture informatique permettant le traitement des données à la périphérie du réseau. Les données sont alors traitées là où elles sont générées ce qui permet d’en réduire considérablement le volume avant de les transférer vers le cloud (ou un data center). Le traitement des données peut relever d’un simple filtre mais les recherches visent surtout à embarquer de l’intelligence artificielle au sein même des objets connectés (capteurs, terminaux). Et l’enjeu est de taille car d’après les prévisions le nombre d’appareils IoT dans le monde devrait presque tripler en passant de 8,74 milliards en 2020 à plus de 25,4 milliards d’appareils IoT en 2030.
L’émergence de l’IA pour l’environnement
L’intelligence artificielle peut constituer un véritable levier pour la transition écologique. Suivant une étude de Capgemini, l’usage de l’IA dans le monde aurait permis depuis 2017 d’aider les organisations à réduire leurs émissions de GES de 12,9%, à améliorer leur efficacité énergétique de 10,9%, à réduire leurs déchets de 11,7%.

Sur les 400 organisations interrogées en 2017, seulement 13% ont néanmoins mis en place des actions en faveur du climat en intégrant des solutions d’IA. Sur ces 13%, 42% ont situées en Europe, 30% en Amériques et 28% en Asie-Pacifique.
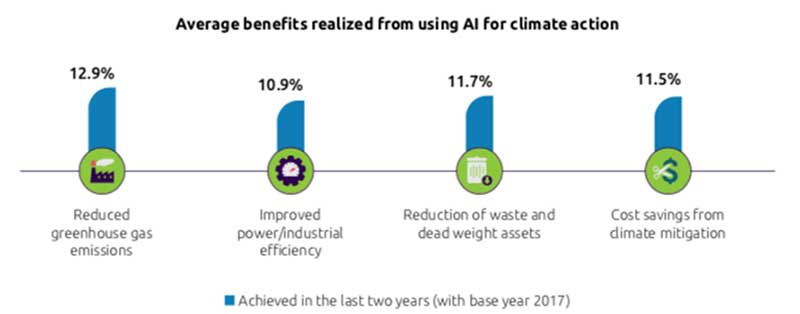
Bénéfices moyens réalisés grâce à l'utilisation de l'IA pour l'action climatique (Source: Capgemini)
Il convient cependant de bien qualifier les gains environnementaux par rapport à ses coûts de mise en œuvre. Le secteur de l’IA (IA for Green) pour l’environnement est très dynamique et de nombreuses applications voient le jour notamment dans les secteurs de l’agriculture, de l’énergie, du transport, des villes intelligentes, de l’efficience énergétique des bâtiments et des datacenters.
Les impacts environnementaux de l’IA
Consommation énergétique
En 2019, dans un article qui a fait grand bruit, des chercheurs de l’université du Massachussetts ont évalué l’empreinte carbone des grands modèles de NLP comme les Transformers, BERT, ELMo ou GPT2. Le plus gourmand des modèles affichait une consommation énergétique de 656 MWh, une empreinte carbone de 626 200 livres de CO2eq (284 tonnes de CO2eq), soit cinq fois l’empreinte carbone sur la vie totale d’une voiture, carburant compris.
C’est en juin 2020 que le modèle GPT-3 publié par OpenAI basé sur un réseau de neurones montre des capacités étonnantes sur la compréhension du langage. Il peut même générer des phrases cohérentes, converser avec des humains, voire de compléter des lignes de code à partir d’un besoin exprimé par écrit. C’est alors le plus gros réseau de neurones jamais construit. GPT-3 compte 175 milliards de paramètres, 10 fois plus que son prédécesseur GPT-2. Aujourd’hui beaucoup de grands modèles d’IA dépassent GPT-3 et cette tendance ne concerne pas que les États-Unis.
Une étude de 2021 de l’université de Berkeley en Californie a montré que l’entrainement du modèle GPT-3 (175 milliards de paramètres) avait produit 552 tonnes de CO2eq pour une consommation d’énergie de 1287 MWh.
Les outils d’évaluation des émissions carbone
La mesure des émissions carbone liées aux projets d’IA est indispensable pour envisager par la suite des actions d’optimisation et de réduction. Depuis peu, les fournisseurs de cloud tels que Google, Microsoft et AWS mettent à la disposition des applications qui permettent à leurs clients de mieux évaluer l’impact de leurs activités. D’autres outils, accessibles en ligne ou en téléchargement sont développés par des chercheurs et sont accessibles gratuitement. L’ensemble de ces outils est présenté en annexe de la thèse.
Ces outils issus d’un domaine de recherche encore émergent permettent surtout de sensibiliser les praticiens de l’IA sur les impacts de leur choix et de leurs usages. Avant de déployer une solution d’IA à grande échelle, une analyse d’impact s’avère donc indispensable.
Amélioration des performances énergétiques de l’IA
Le développement des modèles de Deep Learning a augmenté significativement le nombre de paramètres, les ressources nécessaires à leur apprentissage et la latence des prédictions. On peut identifier 4 leviers d’amélioration des performances énergétiques de l’IA : les algorithmes, le matériel, les données, les pratiques.

Les 4 leviers d’amélioration des performances énergétiques de l’IA
- Amélioration des algorithmes
Techniques de compression
Les techniques de compression s’attachent à optimiser l’architecture du modèle pour le rendre plus petit. Au final, l’idée est de pouvoir assurer son déploiement sur des dispositifs périphériques. On retrouve principalement les techniques dénommées « Quantization » et « Pruning »
Quantization (Quantification)
La quantification consiste à réduire le poids des couches en réduisant leur précision ce qui réduit considérablement les besoins en mémoire et le coût de calcul.
Pruning (Élagage)
Le pruning ou l’élagage est un processus qui consiste à supprimer les connexions entre neurones (et donc les poids associés les moins importants) dans un réseau afin d’augmenter la vitesse d’inférence et de réduire la taille de stockage.
Techniques d’apprentissage
Différentes techniques permettent limiter les ressources nécessaires à l’apprentissage d’un modèle :
Distillation
La distillation repose sur le principe de transférer les connaissances d’un grand modèle vers un modèle plus petit tout en maintenant sa validité. Les modèles plus petits peuvent ainsi être déployés sur des matériels moins puissants.
Apprentissage par transfert (Tranfert learning)
Ce concept du Transfert learning repose sur l’idée de réutiliser un modèle déjà entrainé pour un problème donné (problème source) et de capitaliser sur les connaissances déjà acquises pour traiter un autre problème (problème cible).
Apprentissage continu
En machine learning, l’entrainement du modèle s’effectue traditionnellement sur un ensemble de données d’apprentissage puis, après une phase de test, il est ensuite déployé pour des applications réelles. Le modèle est alors fixe et reste statique. La prise en compte de nouvelles données nécessitera donc un nouvel entrainement du modèle pour être actualisé. L’apprentissage continu ou apprentissage adaptatif permet d’adapter le modèle au flux continu de nouvelles données sans nécessiter un nouvel entrainement complet. Il permet de s’affranchir de ressources matérielles limitées notamment dans le cas de très grands volumes de données.
Automatisation
Optimisation hyperparamétrique
La recherche manuelle des valeurs des hyperparamètres tels que le taux d’apprentissage, le nombre de couches, la décroissance des poids, etc… devient très vite fastidieuse pour optimiser les modèles. Les chercheurs de Google Research présentent des algorithmes permettant d’optimiser de manière automatique ces hyperparamètres pour former des modèles plus efficaces. Cependant, ces méthodes évoquées telles que les « grid search », « random search », « Bayesian Optimization » nécessitent de lancer de nombreux calculs pour évaluer l’influence des hyperparamètres et demandent à être utilisées avec beaucoup de prudence compte tenu des ressources informatiques nécessaires.
Architecture efficace
L’optimisation des architectures d’algorithme ayant apportées de véritables avancées en matière de performances (CNN, Transformer) font actuellement l’objet de nombreuses recherches.
- Amélioration de l’infrastructure matérielle et logicielle
A l’opposé du développement de matériels informatiques toujours plus puissants le courant du TinyML (Minuscule Machine Learning) vise à s’accommoder de fortes contraintes de ressources (mémoire, puissance de calcul) pour la réalisation d’activités de traitement sur des dispositifs périphériques.
- Amélioration des données
L’approche « model-centric » consacrée à l’optimisation des modèles d’IA, largement développée dans les travaux de recherche fait maintenant de plus en plus place à une approche centrée sur les données. Cette approche dite « data-centric », promue notamment par le Professeur Andrew Ng, consiste à travailler sur l’ensemble des données afin d’améliorer les performances du modèle. Il peut s’agir de vérifier la cohérence des étiquettes, de travailler l’échantillonnage des données d’apprentissage et de rester vigilant sur la volumétrie de l’ensemble. Plutôt que de collecter davantage de données, on investit plutôt sur l’amélioration de leur qualité.
- Amélioration des pratiques
Avec les améliorations continues des modèles d’apprentissage profond, le nombre de paramètres, la latence, les ressources nécessaires à l’apprentissage, etc. ont tous augmenté de manière significative. En conséquence, il est devenu essentiel de prêter attention aux métriques du modèle et pas seulement à sa qualité. En synthèse, on retrouve ci-dessous les mesures les plus efficaces classées par ordre d’impact :
Pour les praticiens du machine learning :
- Se poser la question de l’intérêt de déployer du machine learning (expertise métiers)
- Réduire les entrées/sorties de données, les calculs, les copies de données (stockages redondants)
- Sélectionner des architectures de modèles efficaces par rapport au problème à traiter.
- Utiliser des techniques d’amélioration d’algorithme (réduction des calculs de 3 à 10 fois)
- Entrainer le modèle sur le cloud plutôt que sur des serveurs sur site (réduction des émissions de 1,4 à 2 fois)
- Utiliser des processeurs et des systèmes optimisés pour la formation des modèles par rapport aux processeurs généraux (amélioration des performances et de l’efficacité énergétique de 2 à 5 fois)
- Lutter contre le gaspillage de ressources en évitant la recherche sur grille (grid search) pour l’optimisation des hyperparamètres et en réutilisant lorsque cela est possible des modèles déjà formés.
- Quantifier et communiquer les émissions en utilisant des progiciels tels que CodeCarbon, Carbon tracker, Experiment impact tracker (inclus dans le code au moment de l’exécution) ou des outils en ligne tels que Green algorithms et ML CO2. Ces chiffres peuvent être partagés avec la communauté des praticiens pour aider à bâtir des points de repères et suivre les améliorations.
Pour les institutions :
- Privilégier les prestataires dont les solutions d’IA sont soutenables.
- Déployer un data management dédié à la sobriété numérique.
- Déployer si possible les calculs dans des régions à faible émission de carbone.
- Proposer une grille de comparaison énergétique des principaux algorithmes
- Mettre à disposition des outils institutionnels pour le suivi des émissions et les activer sur l’infrastructure informatique.
- Limiter l’utilisation des ordinateurs à 72 heures maximum par processus par exemple afin de réduire le gaspillage des ressources.
- Mener des campagnes de sensibilisation sur l’impact environnemental du Machine Learning.
- Faciliter les compensations institutionnelles pour les émissions ne pouvant être évitées.

Passionné d’innovation et de nouvelles technologies. J’ai travaillé plus de 25 ans dans le secteur de l’enseignement supérieur pour la formation d’ingénieurs. J’ai occupé plusieurs fonctions à commencer par enseignant-chercheur dans le domaine de la construction. J’ai ensuite prise en charge la responsabilité d’un département puis la direction d’une école d’ingénieur.



Un commentaire